Si bien el NetworkManager o WiCD tienen las funciones, via un simple click de raton, de crear redes Ad-Hoc, basandome en http://www.linux-party.com/index.php/menu-up/articulos-archivados/65-wireless/7382-crear-una-red-wifi-adhoc-en-linux-y-con-2-comandos estan los comandos necesarios para hacerlo a mano.
Existen varias formas de configurar un cliente wireless basadas en los
distintos modos inalámbricos, normalmente reducidos a BSS (o modo
infraestructura, que requiere de un punto de acceso) y el modo IBSS
(modo ad-hoc, o modo punto a punto).
Muy practico para clases que tengan que ver con redes y donde “no haya mucha infraestructura”
Este es el primer comando:
[root@gostir ~] iwconfig wlan0 mode Ad-Hoc
Y la segunda linea realmente necesaria:
[root@gostir ~] iwconfig wlan0 essid "nombre_red"
Y hasta le podemos añadir cierta seguridad:
[root@gostir ~] iwconfig wlan0 key s:clave
[root@gostir ~] ifconfig wlan0 ip.ip.ip.ip netmask nn.nn.nn.nn
Y si no tenemos un Apache pero tenemos python, tenemos un servidor web levantándolo así:
[root@gostir ~] python -m SimpleHTTPServer
30 mayo 2013
Alerta: "Mini" alien tiene ADN humano

El pequeño humanoide que asombró a todos hace diez años atrás.
El diminuto ejemplar de una figura
similar a la de un extraterrestre hallado en el desierto chileno de
Atacama hace una década, contiene genética de una persona. Científicos
aseguraron que vivió entre 6 y 8 años y que su cuerpo era escamoso,
además de tener nueve costillas.
Tras una década de descubrirse los restos
momificados de una criatura de seis pulgadas y apariencia
extraterrestre, científicos estadounidenses confirmaron que el organismo
contiene genética humana y que podría tratarse de una especie de mono
más evolucionada.
Un equipo de científicos estadounidenses confirmaron este miércoles que el “mini-extraterrestre" hallado en Chile hace 10 años contiene ADN humano, lo que ha levantado la hipótesis de que el hombre tuvo su verdadero origen fuera del planeta.
La investigación, publicada en un documental titulado Sirius, reveló que los restos momificados de una criatura de seis pulgadas y apariencia 'extraterrestre' contienen genotipo humano.
“Puedo decir con absoluta certeza que no es un mono. Es humano, más cercano a los humanos que a los chimpancés”, explicó Garry Nolan, director de biología de células madre en la Escuela de Medicina de la Universidad estadounidense de Stanford.
Nolan indicó que la criatura “vivió hasta una edad de seis a ocho años. Obviamente, respiraba, comía, metabolizaba” pero agregó que “se pone en duda qué tamaño podría haber tenido cuando nació".
Desde que los restos del pequeño humanoide -conocido como Humanoide de Atacama y apodado Ata- fueron descubiertos en el desierto de Atacama en Chile hace 10 años, las especulaciones sobre su origen no lo abandonaron.
La criatura, provista de dientes duros, contiene cabeza abultada y presentaba una protuberancia extraña adicional en la parte superior. Su cuerpo era escamoso, de color oscuro y, a diferencia de los seres humanos, tenía nueve costillas.
El hallazgo de ADN humana en esta especie ha levantado la polémica teoría de la Panspermia, según la cual la vida existe en todo el Universo y se propaga por medio de meteoritos, asteroides y planetoides; lo que indica que la raza humana podría ser extraterreste y no oriunda del planeta.
Un equipo de científicos estadounidenses confirmaron este miércoles que el “mini-extraterrestre" hallado en Chile hace 10 años contiene ADN humano, lo que ha levantado la hipótesis de que el hombre tuvo su verdadero origen fuera del planeta.
La investigación, publicada en un documental titulado Sirius, reveló que los restos momificados de una criatura de seis pulgadas y apariencia 'extraterrestre' contienen genotipo humano.
“Puedo decir con absoluta certeza que no es un mono. Es humano, más cercano a los humanos que a los chimpancés”, explicó Garry Nolan, director de biología de células madre en la Escuela de Medicina de la Universidad estadounidense de Stanford.
Nolan indicó que la criatura “vivió hasta una edad de seis a ocho años. Obviamente, respiraba, comía, metabolizaba” pero agregó que “se pone en duda qué tamaño podría haber tenido cuando nació".
Desde que los restos del pequeño humanoide -conocido como Humanoide de Atacama y apodado Ata- fueron descubiertos en el desierto de Atacama en Chile hace 10 años, las especulaciones sobre su origen no lo abandonaron.
La criatura, provista de dientes duros, contiene cabeza abultada y presentaba una protuberancia extraña adicional en la parte superior. Su cuerpo era escamoso, de color oscuro y, a diferencia de los seres humanos, tenía nueve costillas.
El hallazgo de ADN humana en esta especie ha levantado la polémica teoría de la Panspermia, según la cual la vida existe en todo el Universo y se propaga por medio de meteoritos, asteroides y planetoides; lo que indica que la raza humana podría ser extraterreste y no oriunda del planeta.
Tomado de: http://www.cronica.com.ar/diario/2013/04/25/46167-alerta-mini-alien-tiene-adn-humano.html
29 mayo 2013
golgu-translate: Google Translate desde la consola
Google Translate desde la terminal
golgu-translate es un script que permite traducir y escuchar la pronunciación de texto usando el servicio de traducción de google.
Idiomas
Soporta los siguientes idiomas:
af sq ar az eu bn be bg ca Simplified Traditional hr cs da nl en eo et tl fi fr gl ka de el gu Creole iw hi hu is id ga it ja kn ko la lv lt mk ms mt no fa pl pt ro ru sr sk sl es sw sv ta te th tr uk ur vi cy yi
Uso
golgu-translate opciones texto
-d: modo debug
-h : mostrar la ayuda
-i : idioma de entrada, ej : -i en
-o: idioma de salida, ej: -o it
-s : traducir y hablar, necesitas el reproductor VLC
-v : mostrar la versión y salir
Si no especificas un idioma de entrada Google trata de detectarlo, y si no especificas idioma de salida el inglés es el predeterminado
Ejemplo
golgu-translate -s -d -i en -o it -t "hello World"
http://opendesktop.org/content/show.php/golgu-translate?content=158355
Lo podes bajar de:
http://opendesktop.org/content/download.php?content=158355&id=1&tan=14569898&PHPSESSID=16e49204491e58ec665a064ee03167f1
golgu-translate es un script que permite traducir y escuchar la pronunciación de texto usando el servicio de traducción de google.
Idiomas
Soporta los siguientes idiomas:
af sq ar az eu bn be bg ca Simplified Traditional hr cs da nl en eo et tl fi fr gl ka de el gu Creole iw hi hu is id ga it ja kn ko la lv lt mk ms mt no fa pl pt ro ru sr sk sl es sw sv ta te th tr uk ur vi cy yi
Uso
golgu-translate opciones texto
-d: modo debug
-h : mostrar la ayuda
-i : idioma de entrada, ej : -i en
-o: idioma de salida, ej: -o it
-s : traducir y hablar, necesitas el reproductor VLC
-v : mostrar la versión y salir
Si no especificas un idioma de entrada Google trata de detectarlo, y si no especificas idioma de salida el inglés es el predeterminado
Ejemplo
golgu-translate -s -d -i en -o it -t "hello World"
http://opendesktop.org/content/show.php/golgu-translate?content=158355
Lo podes bajar de:
http://opendesktop.org/content/download.php?content=158355&id=1&tan=14569898&PHPSESSID=16e49204491e58ec665a064ee03167f1
28 mayo 2013
Masturbacion femenina (De eso, no se habla)
 Si
existe, en nuestra cultura judeo/cristiana, una práctica erótica
condenada y con mala fama, esta es la masturbación, pero si además
hablamos de masturbación femenina el tema comienza a tener categoría de
Tabú. Durante siglos la masturbación estuvo condenada al oscuro rincón
de lo prohibido, la mayoría de las mujeres prefieren mantener esta
práctica intima en secreto y si alguien habla del tema, es absolutamente
normal que en su mayoría, ellas mismas lo nieguen. Claro que esto no es
extraño, ya que durante siglos un manto de censura se encargo de cubrir
esta actividad perfectamente normal y deseable en muchos aspectos. Toda
esta historia estaba montada en especial para evitar la masturbación
masculina, ya que en ese momento no se le atribuían deseos sexuales a
las mujeres (concepción machista de la realidad mediante), y partía del
convencimiento que la masturbación era un acto contra natura (ya que la
única actividad sexual aceptada, era el coito para la procreación). En
el caso de las mujeres sucede lo siguiente, no solo sufrieron esta
condena social por extensión, además se les prohibía todo derecho al
placer sexual, al negar de manera sistemática la existencia de su propia
sexualidad.
Si
existe, en nuestra cultura judeo/cristiana, una práctica erótica
condenada y con mala fama, esta es la masturbación, pero si además
hablamos de masturbación femenina el tema comienza a tener categoría de
Tabú. Durante siglos la masturbación estuvo condenada al oscuro rincón
de lo prohibido, la mayoría de las mujeres prefieren mantener esta
práctica intima en secreto y si alguien habla del tema, es absolutamente
normal que en su mayoría, ellas mismas lo nieguen. Claro que esto no es
extraño, ya que durante siglos un manto de censura se encargo de cubrir
esta actividad perfectamente normal y deseable en muchos aspectos. Toda
esta historia estaba montada en especial para evitar la masturbación
masculina, ya que en ese momento no se le atribuían deseos sexuales a
las mujeres (concepción machista de la realidad mediante), y partía del
convencimiento que la masturbación era un acto contra natura (ya que la
única actividad sexual aceptada, era el coito para la procreación). En
el caso de las mujeres sucede lo siguiente, no solo sufrieron esta
condena social por extensión, además se les prohibía todo derecho al
placer sexual, al negar de manera sistemática la existencia de su propia
sexualidad. Contrariamente
a la creencia social imperante en el pasado y que aun hoy tiene
consecuencias, no es malo masturbarse. Es un proceso imprescindible y
esencial para descubrir y explorar la sexualidad propia durante la
pubertad, reconociendo nuestro propio cuerpo, junto a sus posibilidades
de placer, es mediante esta experimentación como la mujer podrá conocer
sus zonas más sensibles y erógenas, junto a la mejor manera de alcanzar
el orgasmo, para después (en el futuro) poder guiar a su pareja sexual. “Como
afirmaba Sigmund Freud , la sexualidad humana está presente desde que
venimos a este mundo y adquiere su punto máximo en la pubertad con el
pleno descubrimiento de nuestro cuerpo y sus posibilidades.” En
definitiva, en esta primera etapa de la vida la masturbación es una
manera de reconocerse a sí misma, prepararse para las futuras
experiencias sexuales, dado que es el mejor sistema de ir adentrándose
en el terreno del sexo dejando atrás temores e inhibiciones, siendo una
excelente forma de adquirir confianza. Por lo tanto debe quedar en claro
que estamos ante una parte importante del desarrollo psicosexual de los
individuos, quienes de esta manera podrán identificar los patrones de
excitación de su propia respuesta sexual.
Contrariamente
a la creencia social imperante en el pasado y que aun hoy tiene
consecuencias, no es malo masturbarse. Es un proceso imprescindible y
esencial para descubrir y explorar la sexualidad propia durante la
pubertad, reconociendo nuestro propio cuerpo, junto a sus posibilidades
de placer, es mediante esta experimentación como la mujer podrá conocer
sus zonas más sensibles y erógenas, junto a la mejor manera de alcanzar
el orgasmo, para después (en el futuro) poder guiar a su pareja sexual. “Como
afirmaba Sigmund Freud , la sexualidad humana está presente desde que
venimos a este mundo y adquiere su punto máximo en la pubertad con el
pleno descubrimiento de nuestro cuerpo y sus posibilidades.” En
definitiva, en esta primera etapa de la vida la masturbación es una
manera de reconocerse a sí misma, prepararse para las futuras
experiencias sexuales, dado que es el mejor sistema de ir adentrándose
en el terreno del sexo dejando atrás temores e inhibiciones, siendo una
excelente forma de adquirir confianza. Por lo tanto debe quedar en claro
que estamos ante una parte importante del desarrollo psicosexual de los
individuos, quienes de esta manera podrán identificar los patrones de
excitación de su propia respuesta sexual. Esta
práctica continuara durante toda la vida en la mayoría de las personas
(independientemente de los prejuicios y tabúes existentes) y en verdad
no está nada mal que así sea, se tenga o no pareja estable, solo debe
estar supeditada a las necesidades intimas de cada uno y no ha
preconceptos obsoletos y represivos. Son muchas las ventajas y aspectos
positivos que podemos enumerar en la adultez, desde favorecer los ritmos
del deseo, erotismo y genitalidad aun con parejas estables, cuando uno
de los dos está enfermo, no le apetece tener relaciones o no se logra
alcanzar el orgasmo durante la penetración vaginal. Es básicamente una
actividad divertida y liberadora para la mujer, que no debe vivirse con
culpa, sirve para descubrir preferencias, desarrollar fantasías, probar
cosas nuevas en vista a futuros encuentros sexuales, aumenta la libido
(no olviden que en el sexo, la función hace al miembro), es relajante
cuando se está nerviosa o estresada satisfaciendo física y
emocionalmente, fortalece la musculatura pélvica y si no se tiene pareja
ayuda a no perder el ritmo y la costumbre. Además tiene la enorme
ventaja de no necesitar a nadie y poder hacerlo cuando se le dé la gana.
Esta
práctica continuara durante toda la vida en la mayoría de las personas
(independientemente de los prejuicios y tabúes existentes) y en verdad
no está nada mal que así sea, se tenga o no pareja estable, solo debe
estar supeditada a las necesidades intimas de cada uno y no ha
preconceptos obsoletos y represivos. Son muchas las ventajas y aspectos
positivos que podemos enumerar en la adultez, desde favorecer los ritmos
del deseo, erotismo y genitalidad aun con parejas estables, cuando uno
de los dos está enfermo, no le apetece tener relaciones o no se logra
alcanzar el orgasmo durante la penetración vaginal. Es básicamente una
actividad divertida y liberadora para la mujer, que no debe vivirse con
culpa, sirve para descubrir preferencias, desarrollar fantasías, probar
cosas nuevas en vista a futuros encuentros sexuales, aumenta la libido
(no olviden que en el sexo, la función hace al miembro), es relajante
cuando se está nerviosa o estresada satisfaciendo física y
emocionalmente, fortalece la musculatura pélvica y si no se tiene pareja
ayuda a no perder el ritmo y la costumbre. Además tiene la enorme
ventaja de no necesitar a nadie y poder hacerlo cuando se le dé la gana.
Para
nosotros los sexólogos es una herramienta absolutamente necesaria para
el tratamiento de la Anorgasmia, el Vaginismo, Disminución del Deseo y
algunas Fobias Sexuales, siendo incluso un medio adecuado para descubrir
el potencial multiorgasmico de cualquier mujer. Veamos que dice mi
maestro, el prestigioso Profesor Dr. Juan Carlos Kusnetzoff con respecto
a la utilización de la masturbación en la Anorgasmia Femenina.
Importancia de la masturbación en los ejercicios de cura.
- El método aislado más pasible de tornar a la mujer orgásmica, es la masturbación.
- La masturbación frecuentemente resulta en disminución de las inhibiciones acerca del sexo.
- Muchas mujeres experimentan sus orgasmos más intensos a través de la masturbación.
- La masturbación aumenta los conocimientos de la mujer sobre el tipo de estimulación que ella precisa para la excitación sexual.
- La masturbación aumenta la especificidad de la información que la mujer puede proporcionar al compañero, sobre la manera de darle placer.
- La masturbación puede aumentar la vascularización de las estructuras de la región pelviana, aumentando de tal manera, la probabilidad del orgasmo por otros medios. También aumenta la intensidad de los orgasmos, caso ya hubiera algunos.
- La masturbación no reduce la probabilidad de que la mujer reaccione sexualmente a la estimulación del hombre.
- La masturbación es absolutamente normal, común en la mayoría de las mujeres y no trae ningún inconveniente, sostenida por la enorme cantidad de mitos al respecto.
- La masturbación es una buena manera de ayudar a la mujer a aprender a dar placer a sí misma, en vez de esperar que el compañero asuma la responsabilidad de proveer ese placer.
- La masturbación es una agradable "válvula de escape" para la descarga sexual cuando el compañero no está disponible para la interacción sexual por algún motivo (enfermedad, ausencia, desinterés, sueño, etc.)
- La masturbación permite que la persona experimente y emplee la fantasía de maneras que son difíciles de reproducir durante la actividad sexual interpersonal.
- La masturbación es divertida.

Conclusiones.
La forma más sencilla de obtener placer sexual es sin duda alguna la
masturbación, no hace falta nada, ni nadie para conseguirlo (todo el
mundo viene de “fabrica” con todo lo necesario para conseguir placer por
sí mismo). Hoy, la masturbación se ve como un procedimiento
imprescindible en el aprendizaje sexual y no existe ninguna evidencia
científica que permita hablar de consecuencias indeseables para la
salud. Su práctica no debe ser vivida con culpa o vergüenza, masturbarse
es parte de la sexualidad natural y su ejercicio o no deberá ser parte
de una decisión personal, es decir, de la elección libre de cada uno.
26 mayo 2013
Cinco cosas que tenés que saber antes de beber cerveza
 Volver a enfriarla no la echa a perder
Volver a enfriarla no la echa a perderLa cerveza es sensible al oxígeno y a los rayos de sol. Si sacaste una botella de la heladera y te la olvidaste cerrada en la mesa de la cocina, podés volver a enfriarla sin que se altere su sabor.
El color no determina la graduación alcohólica
Existe la confusión de que mientras más oscura es una cerveza, más alcohol tiene. Es falso: el color oscuro está determinado por el grado de tueste de la malta.
No engorda
La cerveza no engorda, apenas genera una leve hinchazón momentánea del estómago. El 90% de su composición es agua y es bastante nutritiva. Eso sí: como cualquier bebida alcohólica, no debe consumirse en exceso.
El sabor amargo es normal
No es cierto que la cerveza nunca deba ser amarga. Ese sabor se debe al lúpulo, uno de los ingredientes fundamentales y más característicos de la cerveza. Hay algunas más amargas que otras en el mercado, pero eso no determina su calidad.
Tirada es mejor
Contra la creencia de que las bebidas embotelladas son superiores, la cerveza de barril (“tirada”) es mucho más sabrosa y de mejor calidad, ya que la temperatura y la composición de la espuma están en su estado ideal.
Tomado de: http://www.acceso365.com/0/vnc/index.vnc?id=cinco-cosas-que-tenes-que-saber-antes-de-beber-cerveza
25 mayo 2013
Desarrollan en Japón una red de telefonía móvil de emergencia usando globos
Tras el terremoto de Japón de 2011, muchas
empresas apostaron por contribuir al sistema de emergencias del país y
garantizar ciertos servicios. Softbank, el operador de telefonía,
trabaja en un proyecto que garantiza el servicio de telefonía móvil
mediante el despliegue de una red de backup emplazando estaciones base en globos.

Con la idea de darle mayor robustez a esta solución, Softbank ha decidido realizar una nueva iteración al proyecto y ha cambiado el camión que conecta los globos-estaciones base a la red por un enlace que es mucho más complicado que falle: las comunicaciones por satélite. ¿Y por qué es más robusta esta solución? En el caso que la red de transporte esté muy deteriorada, la conexión con la red fija sería prácticamente imposible y, sin embargo, el satélite tiene una probabilidad de fallo mucho más baja y sería raro que el enlace no estuviese disponible, garantizando así el servicio en la red de telefonía móvil.
Este proyecto de Softbank, desde que lo anunciaron el año pasado, me ha parecido siempre muy interesante porque es un gran aporte que materializa esa idea de que las telecomunicaciones son un servicio público aunque siempre se vean como un negocio. Esta nueva iteración, sin duda, dotará de mayor robustez al sistema y garantizaría las comunicaciones en caso de desastre y, por lo que ha comentado la propia Softbank, parece que están a punto de desplegar 10 de estos globos por Japón para que, en caso de emergencia, se puedan desplegar.
Tomado de: http://alt1040.com/2013/03/red-telefonia-movil-emergencia-globos
24 mayo 2013
Activar HTML5 en youtube y chau flash!
Sí, tal y como dice el título y si tu navegador lo soporta, ahora es muy sencillo ver los videos de Youtube en formato HTML5, logrando así dejar de lado el reproductor en flash clásico.
 Para lograr esto, solamente hay que ingresar a http://youtube.com/html5 y clickear en la opción de activar la versión de prueba de HTML5. Y listo, podrán ver los videos de dicho portal usando un reproductor en HTML5 sin depender de Flash.
Pero, lamentablemente, no todo es color de rosa, ya que como la misma
página anuncia, todavía no todos los videos están disponibles en este
formato. Aunque vale destacar que aquellos si lo están, vienen en WebM ;).
Para lograr esto, solamente hay que ingresar a http://youtube.com/html5 y clickear en la opción de activar la versión de prueba de HTML5. Y listo, podrán ver los videos de dicho portal usando un reproductor en HTML5 sin depender de Flash.
Pero, lamentablemente, no todo es color de rosa, ya que como la misma
página anuncia, todavía no todos los videos están disponibles en este
formato. Aunque vale destacar que aquellos si lo están, vienen en WebM ;). Tomado de: http://www.thalskarth.com.ar/2011/04/05/tip-activar-html5-en-youtube-y-chau-flash/
23 mayo 2013
¿Cuantos usuarios de linux son necesarios para cambiar una bombilla?
- 1 para postear en el hilo que la bombilla se quemó.
- 1 para sugerir que intente encender la lámpara mediante linea de comandos.
- 1 a quejarse de que el usuario rompió el hilo.
- 1 para preguntar que nueva bombilla va a instalar.
- 1 para advertir de que no debemos utilizar la palabra fuego parareferirse a que la bombilla no funciona, porque no hay combustión y que sería correcto decir que la bombilla se rompió debido a un exceso de corriente eléctrica.
- 25 para sugerir la instalación de todos los tipos de bombillas existentes e imaginables.
- 5 usuarios para decir que el problema de la bombilla quemada, es del upstream y no de la distro. Que hay un bug abierto en la lista de desarrolladores de la bombilla.
- 1 “noob” para sugerir la instalación de una bombilla de microsoft.
- 250 para inundar la casilla de correo electrónico del “noob“.
- 300 para decir que una bombilla de Microsoft, se quedaría azul y tendrías que apagar y volver a encender continuamente para volver a la normalidad.
- 1 ex-usuario de linux que aún frecuenta la lista, para sugerir la instalación de una iBombilla de Apple, que tiene un diseño fresco e innovador y cuesta 250 $.
- 20 para decir que las iBombillas no son libres, y tiene menos funciones que una bombilla estandar que es 20 veces más barata.
- 15 para sugerir la instalación de una bombilla nacional.
- 30 para decir que las bombillas nacionales, son remasters mal hechos de las extranjeras y que no aportan nada nuevo.
- 23 para discutir si debe ser blanca o transparente.
- 1 para recordar que el nombre correcto es GNU/Bombilla.
- 1 para decir que las bombillas son cosa de Winusers y que losusuarios de Linux no tienen miedo a la oscuridad.
- 1 para anunciar finalmente cual será el modelo de bombilla instalada.
- 217 para descartar la elegida y sugerir otra.
- Media docena para reclamar que la bombilla elegida tiene elementos propietarios, y que debería ser elegida otra.
- 20 para decir que una bombilla totalmente libre, no es compatiblecon el interruptor de la lampara.
- La media docena de antes, para sugerir que el interruptor sea cambiado por otro compatible.
- 1 para gritar: “PAREN DE DISCUTIR Y CAMBIEN ESA BOMBILLA POR EL AMOR DE DIOS!”
- 350 para preguntar al usuario anterior de que Dios está hablando, y si tiene pruebas científicas de su existencia.
- 1 para decir que no podemos confiar en las bombillas hechas por las corporaciones y que debemos confiar en las bombillas hechas por la comunidad.
- 1 para postear un link de un archivo ODF que explica como construir unabombilla desde cero (from scratch).
- 14 para quejarse del formato de archivo anterior y pedir que se lo envie en txt o Latex.
- 5 para decir que no les gustó la decisión tomada y van a crear un forkde la instalación electrica de casa e instalar una lampara mejor.
- 1 para postear una serie de comandos que se deben introducir para cambiar la bombilla.
- 1 para comentar que ejecutó las ordenes y recibió un mensaje de error.
- 1 para advertir que los comandos se deben ejecutar como root y finalmente:
- El padre del usuario inicial, que mientras todos discutían, fue al almacen de la esquina y compró la bombilla más barata.
Tomado de: http://www.infognu.com.ar/2013/04/humor-cuantos-usuarios-de-linux-son.html
22 mayo 2013
¿Sabes qué es un Stalker?
 El acoso físico, acecho o stalking en
inglés, es una forma de acoso que consiste en la persecución
ininterrumpida e intrusiva a un sujeto con el que se pretende iniciar o
restablecer un contacto personal contra su voluntad. Stalking es
una voz anglosajona que significa acechar, perseguir y que puede
traducirse por acecho o persecución. El término se usa en el ámbito de
la sociología, psicología, el derecho y las Ciencias Exactas.
El acoso físico, acecho o stalking en
inglés, es una forma de acoso que consiste en la persecución
ininterrumpida e intrusiva a un sujeto con el que se pretende iniciar o
restablecer un contacto personal contra su voluntad. Stalking es
una voz anglosajona que significa acechar, perseguir y que puede
traducirse por acecho o persecución. El término se usa en el ámbito de
la sociología, psicología, el derecho y las Ciencias Exactas.En muchos casos los Stalkers persiguen solamente por diversión, maldad o por algún propósito en si, por ejemplo, que le guste demasiado esa persona sabiendo que no va a poder llegar a ella.
Tipos de Stalkers
Los Psicólogos suelen agrupar a estos individuos en dos categorías: psicóticos y no psicóticos. Muchos de los stalkers tienen algún tipo de desorden psicológico, como por ejemplo esquizofrenia.
Los stalkers persiguen a sus víctimas influenciados por varios factores psicológicos, incluyendo el enojo y la hostilidad, culpa, obsesión, celos, etc.
•Stalkers rechazados: Persiguen a sus víctimas con intenciones de vengarse, buscar perdón, unirse de nuevo después de un rechazo (Divorcio, cortar relación amorosa, etc).
•Stalkers resentidos: Persiguen a la víctima por algo en contra de ella – motivados principalmente por el deseo de asustar y afligir a la víctima.
•Los que desean tener intimidad con alguien: Buscan establecer una relación íntima y amorosa con su víctima. Para ellos, la persona afectada, es el alma gemela que estuvieron buscando durante toda su vida y que nacieron para estar juntos.
•Pretendiente ineficaz: A pesar de su poca capacidad de relacionarse con las personas, tienen una obsesión, o en algunos casos, creen que tienen derecho a establecer una relación íntima con cualquier persona que comparta sus mismos gustos e intereses. Por lo general la víctima que escogen frecuenta una relación estable con otra persona.
•Stalkers depredadores: Espían a sus víctimas y buscan el momento adecuado para atacarla, por lo general, sexualmente.
Como detectar un Stalker
Reconocer a alguien como Stalker es complicado. No se ven como monstruos. Muchos pueden lucir encantadores, lindos y hasta parecer normales, mientras que otros se ven raros, anti sociales y son fáciles de diferenciar entre las demás personas.
Hay una gran variedad de características psicológicas que hay que tener en cuenta a la hora de reconocer un stalker: el humor, ansiedad, desordenes mentales por el abuso de psicofármacos, bajo autoestima, inseguridad social, narcisismo, muchos celos, morbosidad.
Como saber si estoy siendo víctima de un Stalker
•Constantes llamadas telefónicas, aunque se le haya dicho al sujeto que no tome contacto con usted de ninguna manera.
•El sujeto merodea cerca del lugar donde trabaja/estudia/vive.
•Amenazas.
•Comportamiento manipulador. Por ejemplo, el sujeto amenaza con suicidarse de manera que tomes contacto con él para evitarlo.
•Mensajes escritos: Mensajes de texto, cartas, emails, etc.
•Regalos enviados por el sujeto, que aparentan desde lo romántico (Flores, dulces, etc) a lo bizarro (Dientes de perros, plumas ensangrentadas, etc).
•Difamación: El sujeto suele mentir a sus contactos a cerca de la víctima.
IMPORTANTE: El contenido de esta nota es informativo y no suple el diagnóstico médico, por lo que no nos hacemos responsables sobre su uso. Recuerda siempre consultar con un especialista.
Tomado de: http://www.culturizando.com/2011/04/sabes-que-es-un-stalker.html
21 mayo 2013
Las misteriosas palabras que NO puedes tweetear
La leyenda cuenta que cuando el
cofundador de Twitter, Jack Dorsey, era pequeño, su padre le decía
constantemente “Get better” (“¡Mejora!”), por lo que éste prohibió la
frase y no se puede tweetear. Anda, inténtalo. No se publicará.
Tomado de: http://lincinews.com/las-misteriosas-palabras-que-no-puedes-tweetear/
Sin embargo, ¿qué pasa con la leyenda? Es una broma.
Hace mucho tiempo, cuando Twitter no era
una popular aplicación para smartphones, y sólo se podía publicar a
través de Internet o mensajes de texto, para permitirle
a la gente seguirse o dejar de hacerlo, cambiar sus bio y más, Twitter
creó una lista de comandos que al enviarlos por SMS, no se publicarían,
sino desencadenarían acciones.
En consecuencia, cuando tweeteas “get
better”, “get [cualquier otra palabra]” y muchas otras frases, Twitter
las interpreta como comandos de SMS.
Si quieres intentarlo con otras
opciones, puedes poner “Fav [usuario]” para marcar como favorito el
último tweet de alguien y “Suggest” para recibir recomendaciones acerca
de quién seguir. Algunos comandos aún funcionan desde la interfaz web y
desde la aplicación para smartphones. Por ejemplo, si quieres seguir a
alguien con sólo tweetearlo, escribe “follow [usuario sin @]” o “f
[usuario sin @]”. Otros comandos como el misterioso “get”, no funcionan
fuera de SMS. Esto fue descubierto por el usuario @DMI y publicado en
Skeptics, de StackExchange.com.
Además, no hay evidencia de que el padre
de Jack le haya dicho “get better” o lo haya presionado de manera
agresiva para que lograra el éxito. De hecho, el Sr. Dorsey parece ser
un padre bastante relajado que manejaba una pizzería e inspiró el
emprendimiento de su hijo. Según Fast Company, le ayudó a “construir un
modelo de espectrómetro de masas de Lego, rodamientos e imanes, cuando
tenía 11 años”.
Todo esto no significa que el cofundador
de Twitter y CEO de Square no quiera que tú mejores. Es más, cuando
Jack ganó un premio por motivar a otros a empezar su propio negocio, él
le dijo a la multitud: “No esperes lo inesperado… SÉ lo inesperado”.
Tomado de: http://lincinews.com/las-misteriosas-palabras-que-no-puedes-tweetear/
20 mayo 2013
Tutorial básico de SVN / subversion
A continuación una pequeña minireceta sobre cómo crear un pequeño repositorio de subversión en un sistema remoto, donde alojar tus pequeños proyectos de software o webs.
Este sistema te permitirá tener siempre online una copia actualizada tu código y evitar el tener que llevar .tar.gzs de las últimas versiones de un ordenador a otro. También puede servir como repositorio, en un entorno laboral, de webs, scripts o código de cualquier tipo.
Instalar subversion
Es tan sencillo como instalar el paquete correspondiente vía apt-get o yum
1.- Levantamos el daemon de svnserve y creamos un repositorio global en el servidor para todos los usuarios (repositorio por defecto). Esto implica que la gestión de los usuarios se realizará a nivel de servidor (por ejemplo en un fichero de usuarios).
2.- Dejamos que cada usuario aloje sus proyectos en uno o varios repositorios propios en su HOME. Esto sólo necesita acceso SSH abierto en el servidor.
# apt-get install subversion subversion-tools # yum install subversionAhora debemos optar entre 2 opciones:
1.- Levantamos el daemon de svnserve y creamos un repositorio global en el servidor para todos los usuarios (repositorio por defecto). Esto implica que la gestión de los usuarios se realizará a nivel de servidor (por ejemplo en un fichero de usuarios).
2.- Dejamos que cada usuario aloje sus proyectos en uno o varios repositorios propios en su HOME. Esto sólo necesita acceso SSH abierto en el servidor.
Crear repositorio por defecto (SVN)
Si vamos a ejecutar subversión sin SSH, directamente contra el servidor svn, necesitaremos un script de parada y arranque y un repositorio por defecto. Creamos el siguiente script:
Finalmente, arrancamos el servicio SVN:
# cat /etc/init.d/svnserve
#!/bin/sh
#
### BEGIN INIT INFO
# Provides: svnserve
# Required-Start: $local_fs $remote_fs $network $syslog
# Required-Stop: $local_fs $remote_fs $network $syslog
# Default-Start:
# Default-Stop:
# X-Interactive: true
# Short-Description: Start/stop svnserve
### END INIT INFO
test -f /usr/bin/svnserve || exit 0
### Podemos cambiar el puerto en el que escuchar:
OPTIONS="-d -r /var/svn/ --listen-port=3690"
case "$1" in
start)
echo -n "Starting subversion daemon:"
echo -n " svnserve"
start-stop-daemon --start --quiet --oknodo --user root --exec /usr/bin/svnserve -- $OPTIONS
echo "."
;;
stop)
echo -n "Stopping subversion daemon:"
echo -n " svnserve"
start-stop-daemon --stop --quiet --oknodo --exec /usr/bin/svnserve
echo "."
;;
reload)
;;
force-reload)
$0 restart
;;
restart)
$0 stop
$0 start
;;
*)
echo "Usage: /etc/init.d/subversion {start|stop|reload|restart}"
exit 1
;;
esac
exit 0
Damos permisos de ejecución:
# chmod +x /etc/init.d/svnserveAhora lo introducimos en el arranque de la máquina:
Debian: # update-rc.d svnserve defaults CentOS: # ntsysv
También debemos definir y crear el repositorio por defecto para el daemon que corre en memoria, y modificar los permisos de acceso autenticado (auth-access → permitimos escritura), anónimo (anon-access → no permitimos el accesos) y los usuarios/passwords de autenticación en fichero aparte:
# svnadmin create /var/svn/ # egrep -v "^#|^$" /var/svn/conf/svnserve.conf [general] auth-access = write anon-access = none password-db = passwd # cat /var/svn/conf/passwd [users] miusuario = elpasswordComo luego veremos, nada impide que vía SSH cada usuario pueda tener sus propios repositorios adicionales.
Finalmente, arrancamos el servicio SVN:
# /etc/init.d/svnserve startEn algunos tutoriales se aconseja crear los siguientes directorios base:
# svn mkdir file:///var/svn/trunk -m "Crear trunk" # svn mkdir file:///var/svn/tags -m "Crear tags" # svn mkdir file:///var/svn/branches -m "Crear branches"La ventaja de este sistema es que podemos dar acceso a múltiples usuarios gracias al fichero de passwords, así como dar acceso anónimo de sólo lectura.
Crear repositorios individuales para los usuario (SVN+SSH)
Podemos utilizar SVN por SSH si queremos un acceso “personal” a un repositorio a través de nuestra cuenta de trabajo de un servidor o host Linux sin necesitar acceso administrativo (siempre y cuando tenga instalado el paquete de subversion). Normalmente es la forma más utilizada para usuarios individuales (no trabajo en grupo) que quieren guardar sus proyectos o ficheros en un repositorio para evitar el traspaso de ficheros entre diferentes equipos de trabajo (ejemplo: tener la misma copia de código en casa o en el trabajo).
En el caso de utilizar SVN por ssh, no necesitamos arrancar el daemon ni crear este repositorio por defecto. En ese caso, crearemos uno o varios repositorios para nuestro usuario, ubicado donde queramos en el PATH, por ejemplo en /home/usuario/svn:
Si necesitamos acceso de múltiples usuarios vía SSH, lo mejor es crear un usuario común (no nuestro usuario personal) que alojará el/los repositorios.
En el caso de SVN+SSH se nos presentan 2 opciones relativas a la organización de los repositorios:
1.- Crear un único repositorio del que colgarán todos los proyectos:
Creamos un directorio único en el servidor (por ejemplo /home/usuario/svn), creado con “svnadmin create”, el cual alojará todos los proyectos. La raíz del repositorio será dicho directorio, para todos los proyectos. La ventaja de este sistema es la simplicidad del “setup”.
La desventaja de este sistema es que las revisiones del repositorio son comunes a todos los proyectos; es decir, si en un repositorio con 3 proyectos hacemos commit en cada proyecto, la revisión aumenta en 3, no es específica para cada proyecto.
Además, borrar un proyecto es “complicado”: implica regenerar el repositorio a partir de un dump con filtro extraído con “svndumpfilter exclude” (ver reposadmin.maint.filtering).
2.- Crear múltiples repositorios (un repositorio para cada proyecto):
Creamos un directorio único en el servidor (por ejemplo /home/usuario/svn), y dentro de dicho directorio creamos un repositorio para cada proyecto (con “svnadmin create nombreproyecto”). La raíz del repositorio ya no será /home/usuario/svn sino /home/usuario/svn/PROYECTO, según el proyecto con el que queramos trabajar.
La ventaja de este sistema es que cada proyecto tiene su propio sistema de revisiones, y sus propios tags y branches. También, el borrado de los proyectos (repositorios) es muy fácil y simple.
Yo personalmente me decanto por esta opción aunque veremos las 2.
La opción elegida sólo cambia la forma de CREAR EL REPOSITORIO y de hacer LA SUBIDA INICIAL DEL PROYECTO y la DESCARGA INICIAL DEL PROYECTO (digamos que los primeros 10 minutos de uso del repositorio). Después, el uso diario y regular de SVN es igual en ambas opciones.
Crear un único repositorio donde alojar todos los proyectos
Creamos el repositorio en el servidor:
$ mkdir /home/usuario/svn/ $ svnadmin create /home/usuario/svn
Una vez hecho esto, vía SSH podemos ya acceder al repositorio referenciándolo como:
$ export SVNROOT="svn+ssh://usuario@server.com/home/usuario/svn/"De nuevo, se recomienda crear los siguientes subdirectorios:
$ svn mkdir file:///home/usuario/svn/trunk -m "Crear trunk" $ svn mkdir file:///home/usuario/svn/tags -m "Crear tags" $ svn mkdir file:///home/usuario/svn/branches -m "Crear branches"
Repositorio único: Subir por primera vez un proyecto al repositorio
Sea un directorio de código fuente denominado “miproyecto”. Nos situamos en el directorio padre de “miproyecto” y ejecutamos uno de los siguientes comandos:
$ svn import miproyecto svn://server.sromero.org/var/svn/miproyecto
$ svn import miproyecto svn+ssh://server.sromero.org/home/sromero/svn/miproyecto
$ svn import miproyecto ${SVNROOT}/miproyecto
$ svn import miproyecto ${SVNROOT}/miproyecto -m "Upload inicial del proyecto"
Al comando le decimos que importe un directorio específico (svn import miproyecto) y le decimos que lo haga sobre el SVNROOT añadiendo además el subdirectorio del repositorio que alojará el proyecto (miproyecto también en este caso). Esto permite tener múltiples proyectos en cada repositorio, gracias a este path “final” sobre el SVNROOT.
Se nos solicitará entonces la introducción de una línea de texto para “resumir” en qué consiste el cambio realizado. Todos los cambios en el repositorio tienen que tener este “summary” que luego podemos recuperar con “log”.
Como se puede ver en el último ejemplo, podemos agregar el resumen para el log en la línea de comandos (en modo no interactivo) con -m “Upload inicial del proyecto”.
Repositorio único: Descargar una copia del proyecto desde el repositorio
Una vez un repositorio está en un proyecto, podemos “descargar” una copia ya controlada por SVN. De hecho, deberíamos desechar (de momento renombrar) el directorio de proyecto original y trabajar con la copia versionada.
Nos situamos en el directorio de trabajo “padre” y (una vez renombrado el directorio original si existe) ejecutamos lo siguiente (una u otra opción según si tenemos definida o no la variable):
$ svn checkout svn://server.sromero.org/var/svn/miproyecto
$ svn checkout ${SVNROOT}/miproyecto
Esto descargará el proyecto “SVNROOT/miproyecto” recreando el directorio “miproyecto” en el directorio actual.
Usar un repositorio para cada proyecto
Esta puede ser la opción más habitual si no queremos mezclar revisiones y si queremos poder borrar un proyecto concreto.
Múltiples repositorios: creando los repositorios
- Creamos un directorio común del que colgarán todos los repositorios (proyectos). Por ejemplo: /home/usuario/svn/.
- Creamos un repositorio por cada proyecto, con “svnadmin create /home/usuario/svn/proyecto”.
- Preparamos cada proyecto para su subida, creando los subdirectorios trunk, branches y tags. Esta subida implicará un SVNROOT diferente para cada proyecto.
- Subimos cada proyecto a su propio repositorio.
- Ya podemos trabajar con los proyectos. Para esto ya no hará falta definir un SVNROOT diferente por proyecto ya que los directorios ocultos .svn de cada proyecto guardan esta información:
Empezamos creando el directorio común en el servidor SVN:
$ mkdir /home/usuario/svn/
Para cada proyecto a alojar hay después que crear su repositorio en el servidor SVN:
$ svnadmin create /home/usuario/svn/proyecto1 $ svnadmin create /home/usuario/svn/proyecto2
Múltiples repositorios: Subir por primera vez proyectos al repositorio
Supongamos que tenemos en nuestro sistema 2 proyectos bajo /home/usuario/code y queremos alojarlos en el servidor de SVN.
Primero preparamos el proyecto1, creando los 3 subdirectorios trunk, branches y tags:
- trunk → contiene el código fuente del proyecto.
- branches → donde se pueden crear ramas del proyecto.
- tags → donde se pueden alojar “snapshots” del código fuente en un momento dado.
$ cd /home/usuario/code/ $ cd proyecto1 $ mkdir trunk $ mv * trunk $ mkdir branches $ mkdir tagsUna vez estructurado el directorio del proyecto, lo subimos al repositorio:
$ export SVNROOT="svn+ssh://server.sromero.org/home/sromero/svn/proyecto1"
$ svn import proyecto1 ${SVNROOT}/ -m "Agregamos proyecto1 a su propio repositorio"
Nótese que ahora el SVNROOT incluye el subdirectorio “proyecto1”, al contrario que en el caso de múltiples proyectos en un único repositorio.
Repetimos a continuación el proceso para nuestro segundo proyecto:
$ cd /home/usuario/code/
$ cd proyecto2
$ mkdir trunk
$ mv * trunk
$ mkdir branches
$ mkdir tags
$ export SVNROOT="svn+ssh://server.sromero.org/home/sromero/svn/proyecto2"
$ svn import proyecto1 ${SVNROOT}/ -m "Agregamos proyecto2 a su propio repositorio"
Múltiples repositorios: Descargar por primera vez el proyecto del repositorio
Importamos el proyecto “subversionado”, renombrando el directorio original y haciendo un checkout:
$ cd /home/usuario/code/ $ export SVNROOT="svn+ssh://server.sromero.org/home/sromero/svn/proyecto1" $ mv proyecto1 proyecto1.orig $ svn checkout $SVNROOT proyecto1Y lo mismo para el otro proyecto:
mv proyecto2 proyecto2.orig svn checkout $SVNROOT proyecto2
Ahora ya podríamos trabajar con normalidad dentro de cualquiera de los 2 proyectos (svn update, svn commit, etc), y cada uno de ellos estará alojado dentro de su propio repositorio sin compartir estructuras de SVN con otros proyectos.
Múltiples repositorios: Borrado de un proyecto del repositorio
El borrado de un proyecto, se realizará en el servidor con un simple:
$ rm -rf /home/usuario/svn/elproyecto
(sin afectar así al resto de proyectos, y pudiendo volver a generarlo de nuevo con un “svnadmin create” si fuera necesario).
Múltiples repositorios: Import y checkout inicial masivo
Veamos un pequeño “script” que subirá al repositorio todos los proyectos que tenemos bajo un mismo directorio:
En el servidor SVN:
cd /home/usuario/svn
for PROJECT in proyecto1 proyecto2 proyecto3 proyecto4;
do
svnadmin create $PROJECT
done
En nuestro equipo de trabajo:
cd /home/usuario/prog/code
for PROJECT in proyecto1 proyecto2 proyecto3 proyecto4;
do
export SVNROOT="svn+ssh://user@myserver.org/home/usuario/svn/${PROJECT}/"
cd ${PROJECT}
mkdir trunk
mv * trunk
mkdir tags
mkdir branches
cd ..
svn import $PROJECT ${SVNROOT} -m "Agregamos proyecto al repositorio"
done
Con esto hemos subido los diferentes proyectos al servidor SVN, cada uno en un repositorio diferente bajo la misma ruta.
Ahora tenemos que descargarnos los proyectos “subversionados” para trabajar con ellos en lugar de usar los directorios de código fuente originales (que no contienen el directorio oculto .svn):
cd /home/usuario/prog/code
for PROJECT in proyecto1 proyecto2 proyecto3 proyecto4;
do
# Movemos el directorio original como .orig
if [ -e $PROJECT ]; then mv $PROJECT ${PROJECT}.orig ; fi
export SVNROOT="svn+ssh://user@myserver.org/home/usuario/svn/${PROJECT}/"
svn checkout $SVNROOT $PROJECT
done
Esta operación es la misma que tendremos que realizar en otros equipos (ej: en casa) donde guardemos copia de estos proyectos, para tenerlos versionados y apuntando al repositorio desde este momento.
Un apunte final sobre el comando mv del script importador:
mv * trunk
(shopt -s dotglob; mv -- * ..)(con los paréntesis)
Usar subversion
Referenciar el repositorio:
La referencia del repositorio puede ser svn: o svn+ssh: :
- SVN puerto por defecto:
svn://server.sromero.org/var/svn/
- SVN puerto modificado:
svn://server.sromero.org:puerto/var/svn/
- SVN via SSH puerto estándar:
Repositorio único: svn+ssh://server.sromero.org/home/usuario/svn/ Múltiples repositorios: svn+ssh://server.sromero.org/home/usuario/svn/nombre_proyecto
- SVN via SSH puerto o usuario modificados:
Repositorio único: svn+ssh://server.sromero.org/home/usuario/svn/ Repositorio único: svn+ssh://usuario@server.sromero.org/home/usuario/svn/ Múltiples repositorios: svn+ssh://usuario@server.sromero.org/home/usuario/svn/nombre_proyecto export SVN_SSH="ssh -p 24" Repositorio único: svn+ssh://usuario@server.sromero.org/home/usuario/svn/ Múltiples repositorios: svn+ssh://usuario@server.sromero.org/home/usuario/svn/nombre_proyecto
En ocasiones puede ser útil declarar este valor en un “export SVNROOT” para usarlo después en las llamadas a svn.
SVN/SSH no nos pedirá password si utilizamos autenticación sin password por clave pública/privada. En el caso de SSH, en ocasiones se crea un usuario específico “svn” para que sea dueño específico del repositorio.
Subir cambios al repositorio
Cuando hacemos cambios en el código, debemos de subirlos al repositorio (hacer un commit de los cambios). Hay quien hace commit cada vez que hace un cambio acotado (para que gracias al comentario del commit podamos saber qué cambios se realizan cada vez), y hay quien hace un commit al final de largas sesiones de trabajo.
Una vez hayamos decidido hacer el commit, y estando dentro del directorio de trabajo del proyecto, ejecutamos:
$ svn commit $ svn commit fichero_o_directorio $ svn commit -m "Resumen de cambios"
Nótese que no necesitamos especificar el SVNROOT porque viene ya “pregrabado” en el directorio que hemos descargado (directorio oculto .svn).
Descargar cambios desde el repositorio
Si otros compañeros han subido cambios o bien queremos descargar en casa los cambios realizados en el trabajo, podemos hacer un update sobre nuestra copia local (que en algún momento fue descargada con checkout).
$ svn update $ svn update fichero_o_directorio
Agregar/Crear/Mover/Borrar ficheros o directorios al proyecto
En SVN tenemos que “añadir” al repositorio los ficheros NUEVOS que creemos localmente, para que sean también subidos/descargados con los checkouts/updates. También hay que eliminar ficheros remotamente si queremos borrarlos localmente.
$ svn add fichero_o_directorio $ svn mkdir nuevo-dir $ svn move file_dir1 file_dir2 $ svn delete fichero_o_directorio
Ver las diferencias de nuestra copia respecto al repositorio
Si hemos hecho cambios en nuestra copia local “descargada”; podemos ver un diff de dichos cambios con:
$ svn diff $ svn diff fichero_o_directorio $ svn diff | less $ svn diff | vim -
Descartar nuestros cambios locales
Es posible en algún momento que hayamos hecho cambios en algún fichero de nuestra copia local y queramos deshacerlos para empezar de cero con los datos que hay en el repositorio. En ese caso no es necesario realizar un checkout de nuevo, podemos hacer un:
$ svn revert fichero_o_directorioO bien, si queremos revertir todos los cambios (.) o los de un directorio:
$ svn revert --recursive . $ svn revert --recursive directorio
Ver historico de un fichero o del proyecto
Lo siguiente muestra todo el registro de cambios de un proyecto:
$ svn log $ svn log fichero_o_directorio
Ver estado del proyecto
El siguiente comando proporciona un listado de nuevos ficheros, ficheros modificados, y ficheros a borrar en el próximo commit.
$ svn status
Resulta también muy útil para conocer si en el directorio actual hay ficheros sin versionar (a los que falta hacerle el svn add), porque estos aparecen con el prefijo ?:
$ touch new_file $ svn status ? new_file
Flags opcionales para el comando "svn"
Si no estamos usando svn+ssh, puede ser interesante especificar user/pass en línea de comandos:
--username sromero --password XXXXXX
También, para el checkout y para el update, puede ser útil la opción –force.
Con –force podríamos hacer un checkout de un proyecto recién subido al repositorio con un import sobre el directorio “inicial” sin renombrarlo. Es decir, podríamos subir una web al repositorio y hacer un checkout –force en el directorio de la web para “descargar la copia remota” y crear las estructuras .svn sin tener que renombrar el directorio y hacer el checkout (que cortaría la web mientras hacemos el mv + checkout).
Mover un repositorio ya existente
Para mover un repositorio se puede usar switch:
$ svn switch --relocate old-url new-url
Tags y branches de proyectos
En subversion tenemos disponibles las siguientes funcionalidades:
Para crear un tag o un branch, lo haríamos con el comando “svn copy”
- tags → “Snapshot” (foto ó backup) del código (trunk) en un momento dado, para marcar dicho momento en el tiempo del código como un estado concreto (por ejemplo: versión 0.1.0), o para hacer una copia del código antes de realizar alguna acción “invasiva” y de la que podríamos querer volver atrás. Los tags nos permiten así empaquetar el código en versiones específicas o bien volver atrás después de un cambio que no ha salido bien y que no se puede deshacer ya con un revert porque ha tenido commits al repositorio. Los tags son “versiones sólo lectura” del código.
- branches → “Ramas” del código. Es decir, “versiones paralelas” del código que otro equipo de desarrollo pueda querer explorar. Son parecidos a los tags, salvo que pueden modificarse. Por ejemplo, podríamos hacer un branch del código para que otro equipo de desarrollo pruebe a implementar soporte en nuestro programa para otro Sistema Operativo, y que si el desarrollo llega a buen puerto, se haga un “merge” de esta rama con el trunk.
Para crear un tag o un branch, lo haríamos con el comando “svn copy”
$ svn copy trunk tags/0.1.0 -m "Version 0.1.0 del proyecto" $ svn commit -m "Version 0.1.0" tags/ $ svn copy trunk tags/0.1.0-antes-de-probar-SDL -m "Snapshot antes de probar SDL" $ svn commit -m "Snapshot antes de probar SDL" tags/ $ svn copy trunk branches/soporte-android -m "Creamos branch pruebas Android" $ svn commit -m "Branch pruebas de soporte para Android" branches/
También podemos crear un tag o branch no desde la rama de trunk sino desde nuestra copia local (directorio del proyecto), es decir, con cambios aún no subidos al repositorio:
$ svn copy miproyecto ${SVNROOT}/tags/android-funcional -m "Tag con codigo Android Funcional"
Para borrar un tag o un branch, lo haríamos con “svn delete”:
$ svn delete tags/0.1.0-antes-de-probar-SDL -m "Eliminamos el tag: SDL implementado OK" $ svn commit -m "Borrado tag 0.1.0-antes-de-probar-SDL" $ svn delete branches/soporte-android $ svn commit -m "Se borra la rama de soporte para Android"
En realidad, físicamente no se borra el código, sólo se marca el repositorio de forma que ya no “exista” en cuanto a actualizaciones. No obstante, podemos recuperar cualquier número de revisión en cualquier momento con:
$ svn copy ${SVNROOT}/branches/rama-android@15 \
${SVNROOT}/branches/rama-android \
-m "Restaurando revision 15"
Podemos obtener un listado de tags o branches del proyecto con svn list (para restaurar revisiones puede sernos útil también svn log, svn info y svn status).
$ svn list ${SVNROOT}/tags
0.1.0/
Y podemos hacer un checkout de un release concreto con:
$ svn checkout ${SVNROOT}/tags/0.1.0
Una de las pegas de los tags es que son parte del proyecto por lo que cada vez que hagamos checkouts o updates nos los vamos a descargar en ~/proyecto/tags . Si queremos evitar esto, podemos hacer checkout sólo del raíz del repositorio (no recursivamente, -N) y actualizar sólo el trunk:
$ svn checkout $SVNROOT -N PROYECTO $ svn update PROYECTO/trunk
De esta forma sólo descargamos el trunk, y no tags ni branches, por lo que no desperdiciamos espacio en disco local.
Trabajando con ramas (branches)
Existen diferentes políticas al respecto de cómo trabajar con el código y las ramas.
Quizá la más extendida es trabajar sobre la rama principal (trunk) y cada cierto tiempo crear una rama denominada “estable”. El proyecto se continúa después sobre la rama principal y la estable sólo se modificará (durante el tiempo de vida de dicha versión) para corregir bugs (que también se deberán corregir en el trunk si le afectan); las nuevas características o funcionalidades sólo se implementarán en la rama principal.
Así, podemos crear una nueva rama y trabajar sólo sobre ella así:
$ svn info ${SVNROOT}/trunk | grep Revision
# (anotamos el numero de revision actual "REVISION_ACTUAL")
$ svn copy ${SVNROOT}/trunk ${SVNROOT}/branches/stable-1.0 \
-m "Rama estable LA_REVISION_ACTUAL"
Ahora configuramos nuestra copia local como la nueva rama:
svn switch --relocate ${SVNROOT}/trunk ${SVNROOT}/branches/stable-1.0
En este momento, podemos trabajar con nuestra copia local y ya no estaremos trabajando con el trunk sino con “stable-1.0”.
$ svn info | grep URL $ svn update # (hacemos cambios) $ svn commit -m "Bug corregido en blah"
Estos pasos servirán incluso si tenemos cambios en nuestra copia local que todavía no hemos subido al trunk, porque hemos decidido que estén en la nueva rama y no en el trunk.
Convertir nuestra rama en la rama principal
También podemos haber querido crear una rama para explorar una alternativa al código (por ejemplo, cambiar de GTK a QT) y que los cambios hayan tenido éxito y queramos convertir esta rama en la versión principal:
Un primer método es borrar el trunk y convertir el código de nuestra rama en el trunk:
$ svn delete ${SVNSERVER}/trunk
$ svn move ${SVNSERVER}/branches/programa-con-qt ${SNVSERVER}/trunk
$ svn switch --relocate ${SVNSERVER}/branches/programa-con-qt ${SVNSERVER}/trunk
Hacer merge de los cambios de nuestra rama con la principal
El merge de una rama al trunk se realiza con:
$ svn merge -r XXX:YYY $SVNROOT/branches/la-rama $ svn commit -m "Realizado merge de la-rama (XXX:YYY) al trunk"
Siendo XXX la revisión en la cual nació la rama y YYY la revisión actual del trunk.
Para obtener estos datos, podemos:
# hacer un checkout del trunk y de la rama en otro directorio:
$ cd ..
$ mkdir temp
$ cd temp
$ svn checkout $SVNSERVER/trunk trunk
$ svn checkout $SVNSERVER/branches/la-rama la-rama
$ cd la-rama
# encontrar la revisión donde se creó la rama (XXX):
$ cd la-rama
$ svn log --stop-on-copy
# encontrar la revisión actual del trunk ("At revision YYY"):
$ cd ..
$ cd trunk
$ svn update
Esto realizará un merge del código de la-rama sobre el trunk. Si hubiera conflictos de edición de ficheros (puede haberlos), los arreglamos localmente y hacemos un commit para subirlos:
$ vim fichero_que_da_conflictos.c $ svn commit -m "Merge de $ svn commit -m "Realizado merge de la-rama (XXX:YYY) al trunk"
Borrar un repositorio ya existente en el servidor
Simplemente, ejecutampos lo siguiente en el repositorio:
# TODO EL ARBOL DE PROYECTOS/REPOSITORIOS $ rm -rf /home/sromero/svn/ # UN REPOSITORIO CONCRETO: $ rm -rf /home/sromero/svn/PROYECTO/
Para volver a tenerlo operativo habría que seguir de nuevo el proceso de creación (mkdir, svnadmin create, editar conf/svnserve.conf, e importar en él proyectos).
Operativa inicial con SVN (cómo subir un proyecto)
Según si vamos a crear un repositorio común para todos los proyectos, o si vamos a crear un repositorio por cada proyecto, los comandos exactos son ligeramente diferentes (ver las correspondientes secciones al principio de este documento), pero generalizando, son:
1.- Crear el/los repositorios en el servidor.
2.- Establecer variables de entorno (SVNROOT y SVN_SSH si necesitamos cambiar el puerto).
3.- Preparar los directorios de nuestro proyecto (en el caso de múltiples repositorios, crear directorios trunk/branches/tags).
4.- Subir nuestro proyecto o web al repositorio.
5.- Renombrar el directorio antiguo.
6.- Descargar el mismo directorio pero con el control de versiones.
7.- Revisar que la descarga es correcta y que no faltan ficheros.
8.- “Archivar” (guardar, borrar) el directorio de código antiguo.
Operativa regular (trabajar con un proyecto)
A partir de ahora, debemos trabajar sobre el directorio de trabajo creado acordándonos de realizar “svn add” de nuevos ficheros, “svn delete” de ficheros que borremos, y de hacer los commits para subir nuestro trabajo y updates para recuperar el trabajo de los demás.
Aplicación práctica: ficheros específicos del HOME en SVN
Una cosa habitual para las personas que trabajamos con varios PCs (portátil, sobremesa casa, trabajo…) es tener gran cantidad de ficheros de configuración comunes entre todos ellos: .vimrc, .bashrc, .tmux.conf, así como directorios de notas, documentación, etc… En esos casos, cada vez que hacemos una mejora en uno de los ficheros, tenemos que distribuirlo manualmente a los otros equipos (vía correo, scp, o llavero USB).
En este ejemplo, vamos a mantener una copia selectiva de ficheros de nuestro HOME en un repositorio privado online de subversion, de forma que con un simple svn update (incluso podría ser automatizado en el login de nuestro usuario) podamos actualizar nuestro HOME local con las últimas copias de dichos ficheros. No sólo eso, sino que nos protege contra borrados accidentales de ficheros (podemos recuperarlos con un svn update) o para encontrar cambios en los ficheros que hayan producido algún problema (volviendo a revisiones anteriores, etc).
NOTA: nunca debemos subir ficheros con datos sensibles en cualquier caso, como una clave SSH, si no confiamos en la seguridad de dicho servidor.
Por ejemplo: estamos en el trabajo, encontramos una opción fantástica para el fichero .vimrc, la añadimos, hacemos un svn commit -m “Nueva opcion vimrc”, y luego en casa sólo hay que hacer svn update (o bien, como he dicho, ponerlo de forma automática en el arranque o el login del usuario).
Para montar este sistema, primero creamos el repositorio en el servidor:
$ svnadmin create /home/usuario/svn/home
Ahora ya en la parte cliente, creamos un directorio “home” ficticio, vacío, para subirlo al repositorio:
$ cd $ mkdir home $ export SVNROOT="svn+ssh://usuario@server.org/home/usuario/svn/home" $ svn import home $SVNROOT -m "Creado homedir" $ rm -rf ~/home
Finalmente, dentro de nuestro /home/usuario real, hacemos un checkout de “home” para que svn cree un directorio .svn de control en nuestro home.
$ cd /home/usuario $ export SVNROOT="svn+ssh://usuario@server.org/home/usuario/svn/home" $ svn checkout $SVNROOT . --force Revisión obtenida: 0
Este checkout lo tenemos que realizar inicialmente en todos lo /home/usuario de los equipos donde queremos tener sincronizados los ficheros (por ejemplo, casa, trabajo, portátil)…
Ojo, –force sobreescribirá cualquier archivo ya existente, por lo que hay que revisar que no hayamos subido al SVN ninguno que no queramos tener idéntico entre los diferentes equipos (en cualquier caso, se recomienda hacer una copia previa a otro directorio “old” de los ficheros que se sobreescribirán la primera vez, por si acaso).
Desde este momento ya podemos subir ficheros a nuestro repositorio:
$ svn add .vimrc* .tmux.conf .gvimrc A .vimrc A .vimrc.common A .tmux.conf A .gvimrc $ svn commit -m "Subidos ficheros iniciales" Añadiendo .gvimrc Añadiendo .tmux.conf Añadiendo .vimrc Añadiendo .vimrc.common Transmitiendo contenido de archivos .......... Commit de la revisión 1.
Con esto, cada vez que añadamos alguna funcionalidad nueva en el .vimrc, por ejemplo, en casa, podemos hacer un update en el trabajo y disfrutar de “contenidos sincronizados” sin andar enviando ficheros por correo o en unidades USB.
Simplemente tenemos que hacer un svn update en cada sitio para tener regularmente sincronizados los ficheros que tengamos en el repositorio.
# En otro sistema diferente, $ export SVNROOT="svn+ssh://sromero@server.sromero.org/home/sromero/svn/home" $ svn update --force
Además de ficheros podemos añadir directorios completos con sus subdirectorios:
$ svn add docs A docs/notas_subversion.txt A docs/comandos_utiles.txt A docs/tutorial_truecrypt.txt (...) $ svn commit -m "Subido directorio docs"
Si queremos añadir sólo algunos ficheros de un directorio (es decir, ficheros selectivamente, pero no todo el contenido), bastará con que agreguemos el directorio con –non-recursive y luego los ficheros individuales. Esto puede ser útil por ejemplo si tenemos un directorio que tiene algún fichero que DEBE de ser diferente en ambos sistemas:
$ ls -1 bin haz_backup.sh sistema_backup.py wxmylauncher.py $ svn add bin --non-recursive A bin $ svn add bin/sistema_backup.py bin/wxmylauncher.py A bin/sistema_backup.py A bin/wxmylauncher.py $ svn commit -m "Subidos algunos ficheros de bin/"
De esta forma, los updates sólo actualizarán los 2 scripts que hemos marcado, y podemos tener así scripts con el mismo nombre pero distinto contenido en las diferentes máquinas.
Podemos habilitar un script para facilitarnos el “svn update” del home:
$ cat bin/update_home_svn.sh #!/bin/bash # Update home directory from SVN export SVNROOT="svn+ssh://usuario@server.org/home/usuario/svn/home" cd $HOME svn update
Siendo este script otro candidato a mantener en SVN (svn add bin/update_home_svn.sh + svn commit).
Tomado de: http://www.sromero.org/wiki/linux/servicios/subversion/basico
19 mayo 2013
Las 10 bebidas Que Son peores para el cuerpo y soluciones
Consejos saludables. Ya sea que estés tratando de perder peso, mantener
el peso o adoptar un estilo de vida saludable, hablar de las bebidas es
una necesidad. Debido a que no se trata de sentarse en una mesa o a
prepararse para comer, sino de algo mucho más práctico y peligroso, la
mayoría de nosotros no le prestamos mucha atención a los líquidos que se
vierten en nuestros cuerpos, pero debemos! Echa un vistazo a 10 de los
peores.
Las bebidas de zumo
- La mayoría están cargados de azúcar, de elegir uno, se recomienda sólo los etiquetados al 100%.
Batidos de café
- Pueden contener hasta 800 calorías y 170 gramos de azúcar. Para evitar
la sobrecarga elegir algún tipo de leche vegetal, especialmente leche
de almendras endulzada con azucares naturales. Te recomendamos el
artículo donde hablamos de la leche
Aguas saborizadas
- La mayoría también contienen edulcorantes artificiales y falsas
propagandas de vitaminas. Se recomienda seleccionar las que contengan
sólo agua ( agua mineral ) y sabores naturales en la etiqueta. Aquí te
recomendamos leer el artículo sobre las aguas vitaminadas hechas en
casa.
Soda
- El consumo excesivo de refrescos se ha relacionado con la obesidad.
Refrescos de dieta ocasionales están bien, pero hay mejores opciones
para llenar su consumo de bebidas al día. Lee aquí los efectos en el
organismo luego tomar una soda o gaseosa conocida a los 10 minutos
solamente.
Bebidas mezcladas congeladas o juguitos congelados
- Los mezcladores son los culpables aquí, por lo general llenos de colores artificiales, sabores y edulcorantes.
"Saludables" batidos de frutas
- Generalmente los que son los batidos vendidos en los los fast food o
comida rápida y no siempre tienen frutos reales y están llenos de
azúcar. Para una opción más saludable, se recomienda hacer su propio
jugo o batido para que pueda controlar los ingredientes al igual que
este batido de arándanos sabroso sin azúcar añadido. Ver aquí algunos de
nuestros batidos recomendados y receta como muestra la imagen.
El licor fuerte
- Después de 2 bebidas, el riesgo de la obesidad y otros problemas de
salud aumenta. Si va a beber, mantener limitado el consumo y no
excederse.
Limonada ya elaborada
- Evite las gaseosas ya hechas y haga su propia bebida donde seguramente
evitará los conservantes y colorantes artificiales. Optar por
cualquiera menos azúcar o tratar de utilizar la miel para endulzar, que
es otro apòrte de salud invaluable.
Las bebidas deportivas
- Los electrolitos son buenos cuando se ha sudado en exceso, pero la
mayoría de las bebidas también tienen una gran cantidad de azúcar y
conservantes que no necesita.
Las bebidas energizantes
-Es posible obtener una ráfaga de energía, sino que será una solución a
corto plazo, porque es de una sobrecarga de cafeína y el azúcar, ver en
el siguiente artículo detalles de los problemas de salud ocasionados por
las bebidas energizantes.
Tomado de: http://dhfinformaciones.blogspot.com.ar/2012/09/las-10-bebidas-que-son-peores-para-el.html
18 mayo 2013
Así perdieron los humanos las espinas del pene
La mayoría de los mamíferos macho tienen el pene cubierto de espinas de queratina, similares a las uñas, que utilizan para desechar el esperma de otros competidores e irritar a la hembra para propiciar la ovulación. Un estudio realizado por científicos de las universidades de Standford y Pensilvania, en Estados Unidos, revela que esta característica desapareció en el hombre con un fragmento de ADN que se eliminó durante nuestra evolución. Los investigadores también han identificado una región del genoma que ha permitió que nuestro cerebro se expandiera, según publica hoy la revista Nature.
Para llegar a esta conclusión, los investigadores, dirigidos por Gill Bejerano, partieron de la hipótesis de que, en lugar de que el ADN humano tenga ventajas sobre el del chimpancé, "en algún momento de la evolución perdimos algunas cadenas de información genética". Así encontraron 510 secciones de código perdido. A continuación eligieron las regiones eliminadas de ADN relacionadas con hormonas masculinas, así como con el desarrollo del cerebro. Después introdujeron estas regiones de código dentro de ratones para averiguar cómo se expresaban y descubrieron que eran responsables de la pérdida de los bigotes sensoriales y de las espinas del pene, así como del crecimiento del cerebro.
Las espinas del pene son comunes en otros animales, incluyendo a chimpancés, macacos y ratones, pero una morfología más simplificada tiende a asociarse con la conducta monógama de ciertos primates.
Muchos estudios han intentado resolver la cuestión de qué hace al ser humano distinto al resto de organismos buscando características extra frente a las de los familiares evolutivos más cercanos. Esta es la primera vez que se descubren características específicas humanas examinando lo perdido a lo largo de la evolución.
Para llegar a esta conclusión, los investigadores, dirigidos por Gill Bejerano, partieron de la hipótesis de que, en lugar de que el ADN humano tenga ventajas sobre el del chimpancé, "en algún momento de la evolución perdimos algunas cadenas de información genética". Así encontraron 510 secciones de código perdido. A continuación eligieron las regiones eliminadas de ADN relacionadas con hormonas masculinas, así como con el desarrollo del cerebro. Después introdujeron estas regiones de código dentro de ratones para averiguar cómo se expresaban y descubrieron que eran responsables de la pérdida de los bigotes sensoriales y de las espinas del pene, así como del crecimiento del cerebro.
Las espinas del pene son comunes en otros animales, incluyendo a chimpancés, macacos y ratones, pero una morfología más simplificada tiende a asociarse con la conducta monógama de ciertos primates.
Muchos estudios han intentado resolver la cuestión de qué hace al ser humano distinto al resto de organismos buscando características extra frente a las de los familiares evolutivos más cercanos. Esta es la primera vez que se descubren características específicas humanas examinando lo perdido a lo largo de la evolución.
17 mayo 2013
CUPS, como usar y configurar de forma facil las impresoras
Entre los paquetes recomendados se instalen al realizar una nueva instalación, se encuentra cups y cups-pdf.
CUPS: “Common UNIX Printing System” o Sistema de Impresión Común para UNIX, es un potente software que se utiliza para imprimir desde las diferentes aplicaciones instaladas tales como el propio navegador que está usted utilizando ahora para leer este post.
Normalmente, si seleccionamos la instalación completa del GNOME
Desktop Environment, se instala por defecto una aplicación para manejar
las impresoras mediante una interfaz gráfica escrita en Python
utilizando en GTK+: system-config-printer para el GNOME y system-config-printer-kde para el KDE.
Nosotros no recomendamos seleccionar inicialmente ese paquete debido a que la instalación del CUPS viene acompañada de una interfaz web verdaderamente potente
y sobre la cual versará este post. No vamos a escribir en lo absoluto,
un artículo que sustituya a la ayuda que viene con ella, sino a
introducirlos en el fascinante mundo de la impresión en Linux vía CUPS.
Es una verdadera lástima que la Ayuda en línea esté casi en su totalidad en inglés. Pienso que en el sitio oficial del CUPS se pueda encontrar una versión en español. A aquellos que conozcan lo suficiente el inglés como para traducirla, RECOMENDAMOS ENCARECIDAMENTE que lean la ayuda en línea y descubran la potencia de este software, el cual sirve para imprimir desde una estación de trabajo en casa, hasta instalar un servidor de impresión multi plataforma.
A los que sólo sepan español, los pocos párrafos introductorios de
cada página les servirán para iniciarse en el uso de ésta interfaz. CUPS requiere de muchos artículos como éste.
Apuntamos nuestro navegador a la dirección a nuestro localhost por el puerto 631 y se nos muestra la página de inicio del CUPS.
Añadir Impresora
Digamos que tenemos una impresora HP LaserJet 1100 conectada a nuestro equipo. Casi estoy seguro de que ya fue detectada mediante el CUPS, pero supongamos que aun no está conectada y nos van a prestar una similar y queremos estar preparados . Vamos a la página Administración y hacemos clic sobre el botón Añadir Impresora. Inicialmente CUPS busca si hay una impresora conectada. En caso de no encontrarla, se nos mostrará la siguiente página de diálogo:

Supongamos que la tenemos conectada al puerto paralelo LPT #1. Después de seleccionarlo, hacemos clic en Siguiente y se nos muestra otra página de diálogo en la cual llenaremos los datos que nos piden y determinaremos si la queremos compartir o no:

Al presionar Siguiente, se nos muestra otra página
de diálogo mediante la cual podemos seleccionar el fabricante de nuestra
impresora o proporcionar un archivo PPD (Postscript Printer Definition).
Los archivos *.ppd se encuentran en la mayoría de
los discos de instalación de las impresoras. Son archivos de texto
simple que describen las características y capacidades de una o más
impresoras. La Ayuda en línea de la documentación es muy explícita sobre
el uso de éstos archivos y del compilador ppdc.
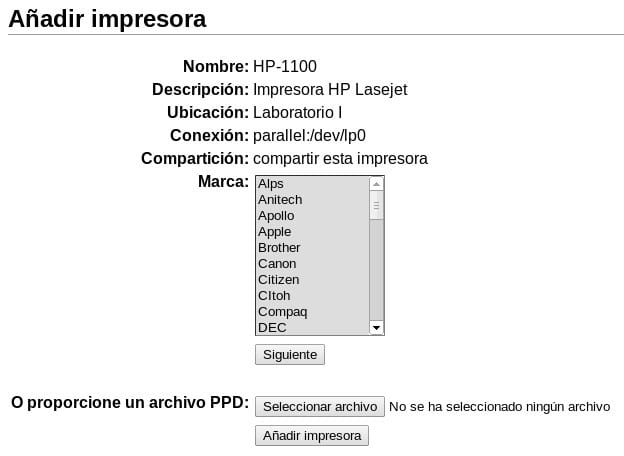
Después que seleccionamos el fabricante HP y clic sobre Siguiente, se nos muestra otro página de diálogo para que seleccionemos el modelo específico:

En ese cuadro seleccionamos HP LaserJet 1100 – CUPS+Gutenprint v5.2.6 (en) y después de presionar Añadir impresora, se nos muestra una página donde la podemos configurar acorde a nuestras necesidades:
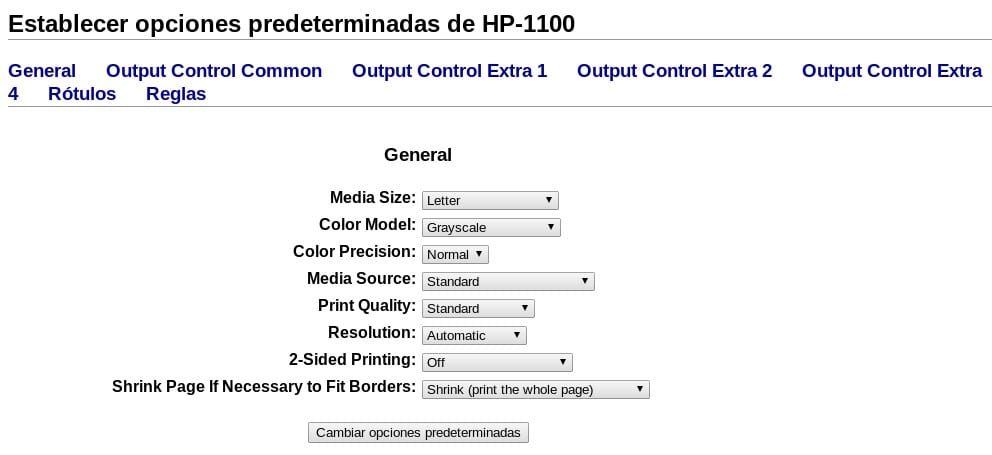
y finalmente presionamos Cambiar opciones predeterminadas.
Después de que CUPS nos confirme los cambios, a los pocos segundos se
muestra la página de estado de la impreora recién añadida, o si estamos
apurados presionamos el enlace HP-1100.

y si seleccionamos en las pestañas superiores la titulada Impresoras, veremos lo siguiente:

Observe como aparece también la impresora cups-pdf con el nombre PDF.
Compartir nuestra impresora.
Queremos compartir la recién instalada HP-110 aun no conectada. De
hecho seleccionamos que queríamos compartirla cuando la añadimos, pero
es necesario realizar un paso más.
Tenemos que ir a la página Administración, y en la parte de Configuración del servidor seleccionar las opciones Compartir impresoras conectadas a este sistema y si deseamos imprimir mediante una URL (recomendado) seleccionamos además la opción Permitir la impresión desde Internet.

Sólo nos resta hacer click sobre el botón Cambiar configuración para que los cambios en el servidor sean permanentes. Esta operación reiniciará CUPS y regresará a la página de Administración.
Para comprobar la impresora compartida,
probé con una red punto a punto configurada de la siguiente forma:- Servidor CUPS: Máquina de escritorio. gandalf.amigos.cu.
IP 10.1.1.1 - Cliente CUPS: Laptop. xeon-pc.amigos.cu. IP 10.1.1.100
Abrí un navegador en la laptop con la dirección http://localhost:631, fui a la página Impresoras, y allí estaba la impresora HP-1100 compartida con la URL http://10.1.1.1:631/printers/HP-1100.
El URL lo averiguamos colocando el cursor sobre el enlace HP-1100 de la página. Que conste que el proceso de encontrar e instalar la impresora en la laptop fue casi inmediato.
Instalarla en un cliente Windows XP
Si queremos instalarla en un cliente Windows XP por ejemplo, vamos a Inicio –> Impresoras y faxes –> Agregar Impresora –> Siguiente. Seleccionamos la opción “Una impresora de red o una impresora conectada a otro equipo” –> Siguiente.
Seleccionamos “Conectarse a una impresora en Internet o en su red
doméstica u organización”, y en la Dirección URL introducimos:
http://10.1.1.1:631/printers/HP-1100
Se nos mostrará el cuadro de diálogo “Elija el fabricante y modelo de
su impresora. Si tiene…”. Seleccionamos el fabricante HP y el modelo HP
LaserJet 1100 (MS) que es el que más se aproxima.
Después de conectada nuestra impresora, imprimimos una página de prueba y comprobamos toda nuestra instalación en Windows.
Consideraciones finales
También si vamos a la interfaz web de nuestro servidor CUPS veremos en la página Trabajos
como se imprimió o no nuestra página de prueba. Sólo añadir que para
cancelar un trabajo de impresión es necesario el nombre y la contraseña
del usuario root, a menos que dispongamos de otros usuarios para administrar los trabajos de impresión.
Cada fabricante de impresora tiene su propio libro y el imprimir
puede volverse una tarea muy complicada. Uno de los “clásicos” en éste
aspecto acorde a mi propia experiencia, es Hewlett Packard, el cual últimamente parece atenerse a la máxima: “Para que hacer las cosas fáciles si las podemos hacer bien difíciles”.
CUPS hace lo máximo por ocultar tanto las
dificultades inherentes a la impresora como las relacionadas con la
aplicación desde la cual queremos imprimir, de forma que podamos
concentrarnos más en el hecho de Imprimir en sí, y no
en el Cómo Imprimir. Por regla general, el único tiempo que necesitamos
para conocer cualquier aspecto de nuestra impresora es cuando la
utilicemos por vez primera. Aun así y con mucha frecuencia, CUPS imagina el “cómo hacerlo” por si mismo.
¿Magia? Para nada. Éste es el mundo de
GNU/Linux.
Tomado de: http://blog.desdelinux.net/cups-como-usar-y-configurar-las-impresoras-de-forma-facil/
Suscribirse a:
Comentarios (Atom)



